- Published on
What happens when you create a pod in Kubernetes?
- Authors
- Name
- Argen


In this blog post, we'll take a deep dive into the lifecycle of a pod in Kubernetes. From the moment you submit a pod definition to the API server, through the various stages of validation, scheduling, and container creation, we'll explore each step in detail.
Section 1: Core Concepts
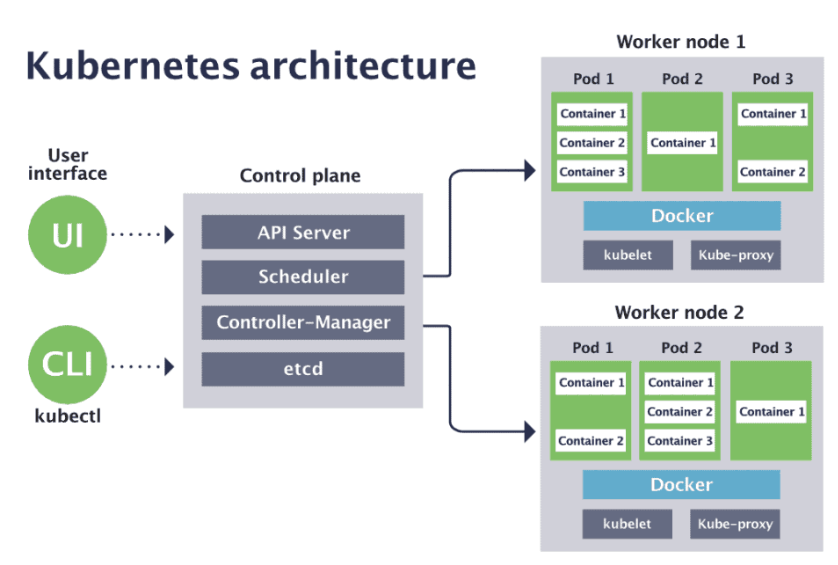
Cluster Architecture
Worker Nodes: Worker nodes are the machines that run containerized applications in Kubernetes. These nodes hold and host the application as containers.
Master Node: The master node manages the Kubernetes cluster. It is responsible for planning how to load containers on the worker nodes, identifying the right nodes, storing information, scheduling, monitoring, tracking the containers, and more.
Components of the Master Node:
etcd:
- A key-value database that stores information about the worker nodes.
- It keeps track of which node holds which container, container load times, and other metadata.
kube-scheduler:
- Identifies which containers should be placed inside the worker nodes.
- Determines the right worker node based on available resources, node capacity, and the types of containers it is allowed to carry.
Controller Manager:
- Handles node operations, traffic control, and damage control.
- Ensures that new containers are made available when existing ones are destroyed.
- Uses Node-Controller for node management and Replication-Controller to ensure the desired number of containers are running in the replication group.
kube-apiserver:
- The primary management component of Kubernetes.
- Responsible for orchestrating all operations in the cluster.
- Allows making necessary changes to the cluster as required.
Components of the Worker Nodes:
kubelet:
- Acts as the leader of each node.
- Manages all activities on these nodes, connects with the master node, receives information about containers, performs container loading, and reports the status of the node and its containers to the master.
- The kubelet is an agent running on each node, listening for instructions from the kube-apiserver and deploying or destroying containers as required.
kube-proxy service:
- A component that runs on the worker node.
- Manages network communication within the cluster and with external networks.
- Configures connections between containers, such as between a web server container and a database server container on another node.
The ETCD
The etcd is a key-value database storing information in documents or pages. Each document contains all the relevant information for an individual component, with fields that may vary between documents.
- After installing and running etcd, it listens on port 2379 by default.
- The
etcdctlcommand-line tool allows storing and retrieving key-value pairs.
Storing Data:
./etcdctl set key1 value1
./etcdctl put key1 value1 # in ETCDCTL_API version 3+
In Kubernetes, the etcd data store contains information about the cluster, such as nodes, pods, secrets, accounts, roles, role bindings, and more. Every change in the cluster is updated in etcd.
If the cluster is set up using kubeadm, it deploys the etcd server as a pod in the kube-system namespace.
To list all keys stored by Kubernetes:
kubectl exec etcd-master -n kube-system -- ./etcdctl get / --prefix -keys-only
Example: What happens when you create a pod?
- The request is authenticated and validated.
- The API Server creates a pod object but doesn't assign it to a node.
- Updates the etcd server with the new information.
- Informs the user that the pod has been created.
- The scheduler monitors the API Server, finds the new pod without a node, and assigns it to a suitable node.
- The kube-apiserver updates etcd with the new information and informs the kubelet of the assigned worker node.
- The kubelet creates the pod on the worker node and instructs the container runtime engine (e.g., Docker) to deploy the application image.
- The kubelet updates the API Server, which in turn updates etcd.
1. Submitting the Pod Definition
The process begins when you submit a pod definition to the Kubernetes API server using a command like kubectl create -f pod.yaml or kubectl run.
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: nginx-container
image: nginx
2. API Server Authentication and Validation
When the request reaches the kube-apiserver, it undergoes several checks:
Authentication
Authentication: The API server verifies the identity of the user making the request. Kubernetes supports multiple authentication methods, such as client certificates, bearer tokens, and external authentication providers like OIDC.
Example:
- Client Certificates: A user with a valid client certificate submits a request to the API server.
- Bearer Tokens: A user includes a bearer token in the request header for authentication.
- OIDC (OpenID Connect): A user logs in through an external identity provider (e.g., Google) and receives an ID token for authentication.
Authorization
Authorization: After successful authentication, the API server checks if the user has permission to perform the requested operation. Kubernetes uses Role-Based Access Control (RBAC) to manage permissions.
Example:
- RBAC Policy: A user wants to create a pod in the "development" namespace. The API server checks the user's roles and role bindings to determine if they have "create" permissions on pods in that namespace.
Admission Controllers
Admission Controllers: These are plugins that can modify or reject requests. Examples include ResourceQuota, which ensures resource limits are not exceeded, and PodSecurityPolicy, which enforces security standards.
Examples:
- ResourceQuota: A user submits a request to create a pod that requests 4 CPUs. The ResourceQuota admission controller checks if the namespace's CPU quota allows for this request.
- PodSecurityPolicy: A user tries to create a pod with privileged access. The PodSecurityPolicy admission controller checks if the pod meets the security standards defined by the cluster policies.
Validation
Validation: The pod definition is checked against the Kubernetes API schema to ensure it is correctly formatted and contains all required fields.
Example:
- Schema Validation: A user submits a pod definition with a missing "spec" field. The API server's validation step checks the pod definition against the Kubernetes API schema and rejects the request due to the missing required field.
If all checks pass, the API server proceeds to the next step.
3. Persisting the Pod Object in etcd
Once validated, the pod object is persisted in etcd, the key-value store used by Kubernetes to maintain the state of the cluster. This persistence step ensures that the desired state of the pod is recorded.
Detailed Explanation
When a pod definition is submitted and passes all the authentication, authorization, admission, and validation checks, it needs to be stored in a way that Kubernetes can reference it to maintain the desired state of the cluster. This is where etcd comes into play.
How etcd Works:
Distributed Nature: etcd is a distributed key-value store, which means it runs on multiple nodes to ensure high availability and fault tolerance. If one node fails, the data is still accessible from other nodes.
Consistency: etcd ensures strong consistency, meaning all clients see the same data at the same time, which is crucial for maintaining the correct state of the cluster.
Key-Value Storage: In etcd, data is stored as key-value pairs. For Kubernetes, the keys might represent different Kubernetes objects like pods, services, and configurations, while the values are the definitions of these objects.
Watch Mechanism: etcd supports watching keys for changes. Kubernetes components like the API server, scheduler, and kubelets watch for changes to specific keys in etcd to react to updates in real time.
By persisting the pod object in etcd, Kubernetes ensures that the desired state of the pod is recorded and can be managed effectively, even in large and dynamic environments.
4. Scheduler Detection and Assignment
The kube-scheduler continuously monitors the API server for new pods that do not have an assigned node. Upon detecting the new pod, the scheduler evaluates the current state of the cluster to identify the most suitable node for the pod based on resource requirements, policies, and constraints.
Example Criteria for Node Selection
- Available CPU and Memory: Ensuring the node has enough resources to run the pod.
- Node Affinity/Anti-Affinity Rules: Constraints that specify which nodes are preferred or avoided based on labels.
- Taints and Tolerations: Mechanisms to repel or attract pods to nodes.
- Pod Affinity/Anti-Affinity Rules: Constraints that specify pod co-location preferences.
- Custom Schedulers: Users can define custom schedulers for specialized scheduling needs.
After selecting the appropriate node, the scheduler updates the pod's specification with the node assignment.
5. Kubelet on the Worker Node
The kubelet on the assigned worker node detects the new pod assignment through the API server. The kubelet is responsible for managing the lifecycle of pods on its node.
Responsibilities of the Kubelet
- Container Creation: Interacts with the container runtime to create and start containers.
- Volume Mounting: Ensures that any specified storage volumes are mounted.
- Network Setup: Configures networking for the pod, including setting up the network namespace and assigning an IP address.
- Health Checks: Monitors the health of the pod and its containers, reporting status back to the API server.
6. Container Creation and Startup
The kubelet interacts with the container runtime to pull the necessary container images from container registries. Once the images are available, the kubelet creates the containers as specified in the pod definition.
7. Pod Status Update
As the containers are created and started, the kubelet updates the pod's status in the API server. The status includes details such as container states (e.g., running, terminated, waiting), start times, and any error messages if container creation fails.
Example Pod Status
status:
phase: Running
conditions:
- type: Initialized
status: 'True'
- type: Ready
status: 'True'
- type: ContainersReady
status: 'True'
- type: PodScheduled
status: 'True'
hostIP: 192.168.1.1
podIP: 10.1.1.1
startTime: 2023-06-27T14:00:00Z
containerStatuses:
- name: nginx-container
state:
running:
startedAt: 2023-06-27T14:01:00Z
lastState: {}
ready: true
restartCount: 0
image: nginx:latest
imageID: docker://sha256:abc123def456
containerID: docker://abcdef1234567890
8. Service Discovery and Networking
If the pod is part of a service, the kube-proxy component on each node updates the IP table rules to ensure network traffic is correctly routed to the pod. This step allows other pods and services within the cluster to communicate with the new pod.
Service Types
- ClusterIP: Exposes the service on a cluster-internal IP. This is the default type.
- NodePort: Exposes the service on each node’s IP at a static port.
- LoadBalancer: Exposes the service externally using a cloud provider's load balancer.
9. Pod Lifecycle Management
The kubelet continues to monitor the pod’s containers to ensure they are running as expected. It handles restarting containers if they fail, based on the pod’s restart policy (e.g., Always, OnFailure, Never).
Restart Policies
- Always: Restart the container regardless of the exit status.
- OnFailure: Restart the container only if it exits with a non-zero status.
- Never: Never restart the container if it exits.
Health Checks
- Liveness Probe: Indicates whether the container is running. If the liveness probe fails, the kubelet kills the container, and the container is subjected to the pod's restart policy.
- Readiness Probe: Indicates whether the container is ready to respond to requests. If the readiness probe fails, the endpoints controller removes the pod's IP address from the endpoints of all services that match the pod.
- Startup Probe: Indicates whether the application within the container has started. If the startup probe fails, Kubernetes restarts the container.
Conclusion
The creation of a pod in Kubernetes involves a series of orchestrated steps that ensure the desired state of the application is achieved and maintained. From submitting the pod definition to the API server to the actual creation and management of containers on a worker node, Kubernetes automates this complex process, providing a robust and scalable platform for running containerized applications.
Understanding these steps helps in diagnosing issues, optimizing performance, and effectively managing Kubernetes clusters. Whether you are a beginner or an experienced Kubernetes user, knowing what happens under the hood when you create a pod is essential for mastering Kubernetes.